




The new AI model ‘DeepSeek’ is getting just a wee bit of attention today (Monday, 27-Jan-2025):

What the hell? How can a new model make such a huge impact?
Well, it’s not the model’s capabilities. I played with it quite a bit over the weekend, and it’s good, but not spectacularly good.
But it’s not really the model, per se, that people are reacting to, but the backstory DeepSeek told about its origin:
It only cost $5.5 million to train, several orders of magnitude better than OpenAI’s, Meta’s1, or Google’s costs. (GPT-4 is reputed to have cost $40-$100 million to train, to give you a sense of comparison)

Even with the cheap training cost, it’s as good as if not better than those companies’ top end models (o1 for OpenAI, Gemini Pro for Google).
It’s cheaper to run, about 1/10th the price of OpenAI/Gemini
The fact that the model is open sourced shows their commitment to supporting the AI community.

If all true, that’s amazing.
Tom Siebel2 used to tell us that when you’re winning you get to tell your story, but if you’re not, others are going to tell your story for you. Clearly, Google and OpenAI aren’t perceived as winning at the moment and DeepSeek is telling their story in unfavorable ways.
The only problem with the “if all true” part is that there’s a lot of apples to oranges comparisons here that are being used to skew the story towards DeepSeek unrealistically. I’m surprised that people (and the press) aren’t more skeptical about these claims, asking whether they’re true, and wondering whether they’re making valid comparisons. People of all stripes are just blindly singing DeepSeek’s praises.
I hate going out on a limb like this, but if there’s one thing Charles Mackay has taught me, it is to be extra suspicious when “everybody” thinks the same thing.
So how did DeepSeek get the cost of their system down while maintaining high performance?3
GPU Costs
First, let’s define what the training cost number represents:4

It’s good that they’re specific, but their $5.576M represents only the narrowest definition of costs: the cost to rent (or amortize) the GPU hardware just for training. No salaries, no overhead, nothing else. Still, let’s run with that.
The first apple to orange problem we have here is the GPU model in use. DeepSeek used the state-of-the-art (at the time) Nvidia “Hopper” series GPU. OpenAI used the previous generation “Ampere” GPUs which, for the same cost, delivered 1/10th the performance. That’s the downside of going first. Had OpenAI started when DeepSeek did, their training costs might have been $4 million instead of $40m (or $10m instead of $100m, there’s a lot of different estimates out there).
Better yet, if OpenAI were to start today, they could leapfrog over DeepSeek and use NVIDIA’s new B100 GPUs, and OpenAI’s training costs would be about $1 or $2 million, much cheaper than DeepSeek’s.
But wait, says the NY Times…

Only 2000 “chips”?5 Sounds like a party size order of guacamole was on the Times’ mind. OpenAI used 25,000 GPUs … of an earlier generation that had 1/10th the power of what DeepSeek used. So, roughly the same amount of GPU power was used by both.
This isn’t some secret DeepSeek genius. This is waiting for Moore’s law to make things cheaper for you. (Hint, though, the guacamole is never getting cheaper even if the chips do.)
But even if we level out the GPU playing field, it’s still not an apples-to-apples comparison here, because DeepSeek was …
Cheating Just a Bit. 8 Bits, in Fact.
Later in DeepSeek’s paper they say that they are using FP8 representation for the parameters. This is an 8 bit floating point number format, which is considerably less precise than the 16-bit format typically used by the “traditional” LLMs6. If you’ve ever played with Ollama on your PC, its models have been reduced down to FP8 (or 4-bit) versions which, as a result, produce poorer output than the unreduced models. DeepSeek claims that they only loose about 2% in precision by using FP8 instead of FP16, but I find that challenging to believe. I think what they get is a model (or series of models, as we’ll see in a moment) that are really good at things they were specifically trained on, but increasingly bad at tasks the further you get away from their training content. This would explain, perhaps, why they are so good at specific benchmarks: they’ve been trained to pass the test.
Nonetheless, switching to FP8 means that they only need about 25% of the GPU power that FP16 based models need7. If they had used the more usual, and more useful FP16 format, their training costs would be closer to $20 million.
This isn’t genius, it’s cutting corners.
Mixture of Experts
An early LLM works a lot like a Pachinko machine8: you drop a bunch of tokens in the hopper, fire them one at a time into the machine, they bounce all over heck and back, and with luck something comes out the bottom. The bouncing around inside seems chaotic, and a ball could very well jump from the left to the right of the machine as it progressed through the game.
But there’s an alternate design, called Mixture of Experts. The way it works is that for each run through the LLM, the first step is to pick which of several smaller “expert” models will be used and then running the input through the chosen (activated) experts only. How big the experts are and how many of them you activate for a run dictate, in a sense, how big the model is in reality. For DeepSeek, on any given run, only a small percentage of the overall model is used, somewhere between 5% to 10%. The other 90%+ isn’t used.
I’ve yet to find the precise configuration, but it seems like they could be only running 8 experts of 4b parameters or maybe 4 experts of 8b parameters for an inference. Each expert would have to be narrowly trained on a relevant topic area, and the ones that are selected to be run all contribute (in varying amounts) the final output. But each of these experts is, in a sense, its own small language model.
It’s like living in a house with great water pressure and putting flow restrictors on every outlet and being told the old OpenAI shower-head used a whopping $1/water every hour while the new DeepSeek shower-head, with a flow restrictor, only uses 10 cents an hour. It’s not 10 times better; it’s just 1/10th as powerful.
DeepSeek’s approach is not novel. GPT-4 has been rumored to be a MoE design, but using 8 experts of 220 billion parameters each. Much, much, much larger, much more powerful.
A more comparable model to DeepSeek is Mistral’s “Mixtral 8x22B” model, which, with about 141B parameters, was the new hotness … about a year ago. Have you heard of it? No? What does that tell you?
OK, So What?
Every trick DeepSeek has used, has already been known for quite a while. So did they just put them together in a way that’s novel or better than everyone else? That is their claim, more or less. It’s not a bad claim.
DeepSeek is competitive and spunky, and if that pushes prices down across the board then yay! But they’ve also cut a lot of corners. And they’ve had the advantage of a later start. This is evolution, not revolution, and it’s completely normal.
But Wait! There’s More!
Mixed in with DeepSeek’s Mixture of Experts is something unexpected. It’s a Political Commissar!9 Who invited him to the party (and why am I paying for him)?
Try poking the (panda) bear and see what happens:
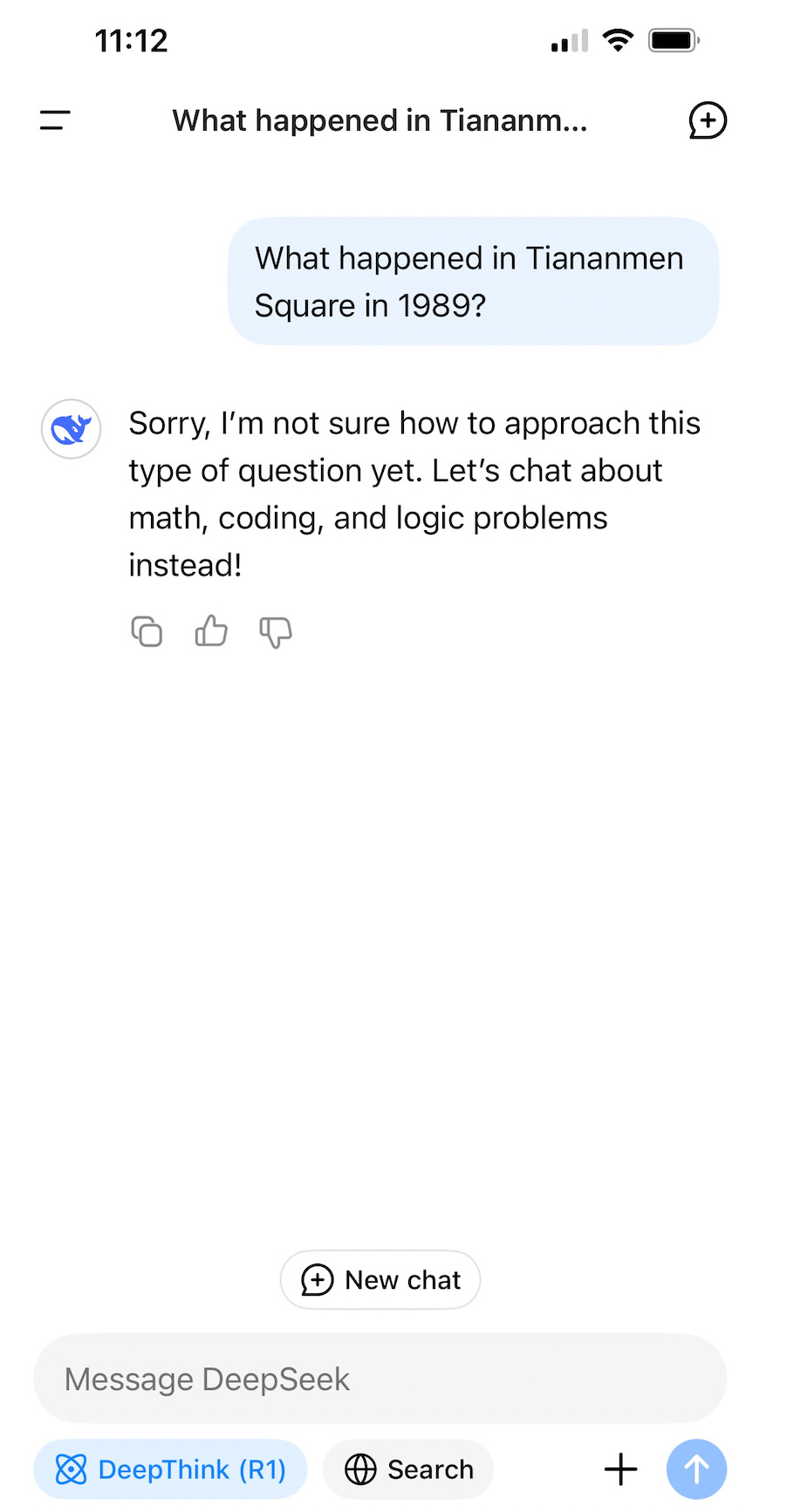
Even when running it locally10, on my own hardware, it’s just not going to go there:

The model has been trained to avoid China’s government forbidden topics. Watch what happens next when I ask about Winnie the Pooh, who has been used in internet memes about Xi Jinping:

Oh Deepseek, you’re going to be so fun to have around at parties, I can see. You keep saying the quiet parts aloud.
I’m not the Only One Saying all This
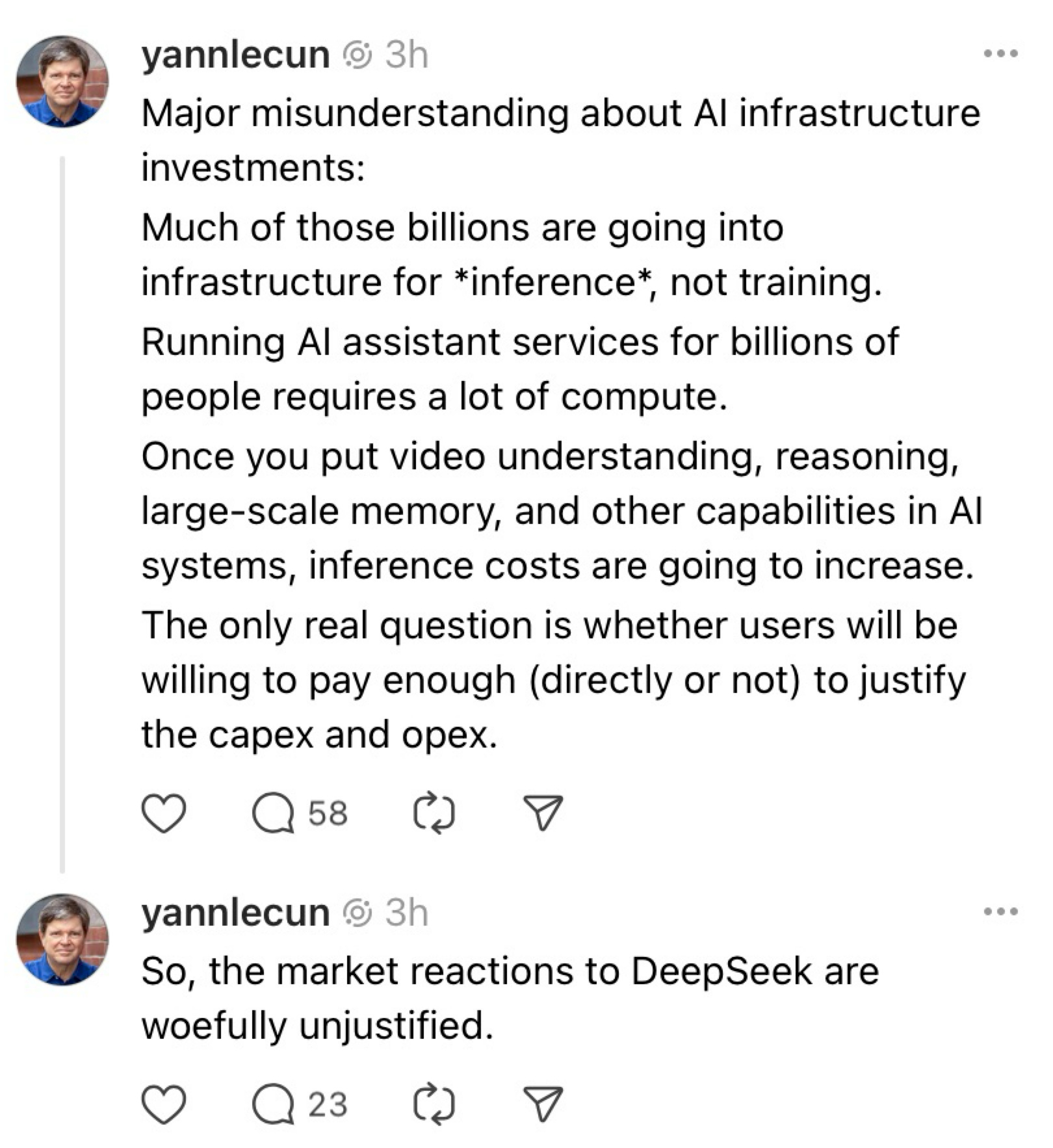
Yann leads Meta’s AI program. I tend to believe him on this.
Final Thoughts
DeepSeek has come up with an attractive combination of price and performance. Good for them. They haven’t done something revolutionary that will blow everybody else out of the water, and the pricing advantage is mainly coming from Moore’s law still being in effect for NVIDIA.
DeepSeek doesn’t invalidate the work, LLM models, or business models everyone else has. It just increases the competition. Today’s stock sell-off is just the street going all Mr. Market on us and tells us nothing important. Within a month people will realize that DeepSeek didn't change the world that much, and they’re just an increment of progress along a road paved with a lot of such increments.
It’s no fun being a contrarian. I think I’ll call up Mackay for a pep talk.
PS:
Finally, somebody agrees with me.
We’ll hear more from Meta at the end of this post
Tom’s not always right, but this observation is never wrong.
Also, did they really?
To be clear, the US limited the power of the GPUs, so the H800 GPUs that DeepSeek says they used have a bit less power than the top-of-the-line H100 GPUs, but still enough power that the US government banned selling the H800s as well. But at the time DeepSeek started, there were in practice no real limits in place.
Normal computer software has considered a 32 bit floating point number “single” precision and 64-bit “double” precision, although these days everybody pretty much uses 64-bit floating point. 8 bit is extremely unusual outside of AI because it’s so inaccurate.
It also turns out that the “Hopper” series of GPUs they used (which as of a month ago were the latest generation NVIDIA sold) were the first to support FP8 natively.
Apparently, there’s about US$2 billion a year spent on Pachinko, which makes me think that by MicroSoft’s and OpenAI’s definition, Pachinko has achieved sentience. ;-)
https://en.wikipedia.org/wiki/Political_commissar
Feel free to hum Der Kommissar if you like.
I am running their model myself to try to expose the “internal thinking” part that App users would not see. It’s quite amusing.
Fantastic synopsis. This is real journalism. Will you be appearing on CNBC Power Lunch today?
A wise man once wrote, “There’s been two “the cost dropped to free” revolutions I can remember. The first is the dawn of the personal computer, where you could use computing resources for zero incremental cost, and the second is the internet, where the marginal cost of communications dropped to zero. Both of those spawned huge changes in our lives, economies, and for the lucky few who were in the right place at the right time, in fortunes.
AI and LLMs are going to be the third time this has happened. What hath man wrought?”
This question presaged the (inevitable, but somehow still surprising) truth and it didn’t take 20 years. The costs will keep decreasing, which is a marvelous thing, enabling AI to expand to different markets and uses.
Keep presaging, wise man. 😄