
Nobody Goes There Anymore, It’s Too Crowded
OpenAI has growing pains

For the last week or so I’ve been struggling to get my demos to be reliable and quick. Stubbornly, they’ve remained unreliable and slow. The reason? OpenAI is overwhelmed.
It’s now reached the point that no matter how patient I tell Salesforce to be, it times out on moderately complicated processes. Simple (but useless) stuff is no problem, but any sort of serious task dies.
There’s a website that tracks the response time for OpenAI1; here’s a recent screenshot:
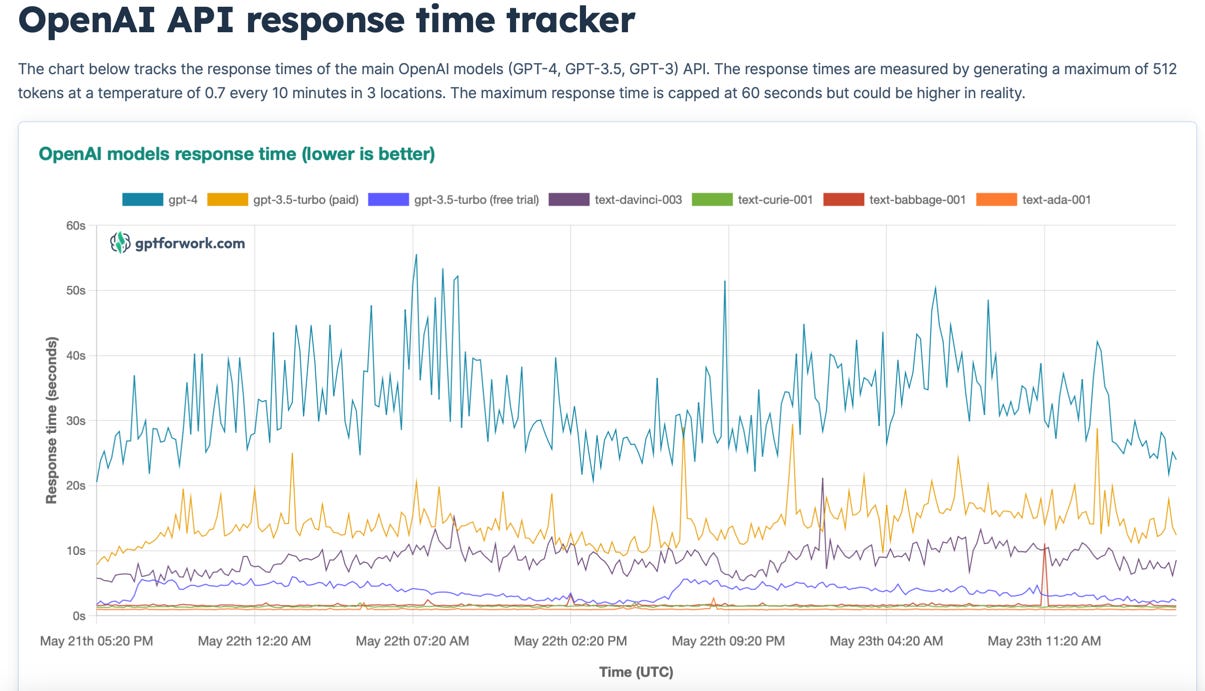
The line at the top, demonstrating the slowest performance, is GPT-4’s, which is generally needed for the more sophisticated problems. Worse, the chart probably represents a best case as the test request is fairly simple. The reality is I’m seeing 90+ seconds2 in response time for real-world problems.
Given what I’ve read, I don’t expect OpenAI to fix the responsiveness problem very quickly. There’s two takeaways I have from this:
It’s going to be a lot more complicated to interface reliably to OpenAI than I might have expected at the beginning (… when OpenAI was a lot less burdened).
Can OpenAI actually scale up to meet the demand (especially given that GPU hardware for AI is in short supply)? Or is this something that’s going to plague them (and us) for a long time.
It’s frustrating, because there’s a lot of ideas (and even code) that just won’t work with the current state of things. Nevertheless, there are ways to get around the problem3, but I’d hate to think the salad days of LLMs are over already!
So when people talk about all the wondrous things AI is going to do and all the jobs I’ve eliminated, I feel like people are waxing poetic about a Mercedes 240D from the late 70s. Yes, it looks great and will drive a million miles4. But when 0 to 60 is given as “eventually”5, there’s only much use for it in modern day driving.
In theory, you can get 120 seconds of patience out of Salesforce, so this would still work. The reality is harsher than that because the default vf remoting time out is 30 seconds and there’s no way to change that for Integration Procedures, OmniScript, etc. So any OpenAI call that takes longer is dead in the water using the standard, simple techniques. Definitely a WTF moment when I realized that.
Async, chaining, etc. Much more complicated, alas.
And then another after an overhaul.
OK, ~20 seconds. Assuming you live that long after merging onto the freeway. Or as posters in this forum suggest “If you're interested in the 0-60 time of the 240D..........you shouldn't be purchasing it.”
Hey, Charles! Thank you so much for these posts. Love 'em! I've given your "insurance recommender" a try, and have modified it to be a "cpq rules recommender". But I find most of my requests are failing with a "Read timed out" error message. At different times in the day, they will work. But they mostly fail with that message...making it hard to demo. I tried setting the timeout on the callGPT element in the IP to 20000, but no dice. I am doing this in a CME org, but also tried an OmniStudio core org, same thing. Any suggestions?