

In recent posts, I talked about the need for testing generative applications and the challenges in doing so. The intensity of this need varies based upon whom the content is for (employee, partner, customer) and how likely the content is to be reviewed before being delivered. A chatbot is risky; a document summarization tool is not. The challenges come because LLMs will generate varied outputs for the same input unless you work very, very hard to constrain them1. The variations usually are innocuous but you cannot be sure, especially after a model upgrade, and those happen all the time. Salesforce has one approach that computes a toxicity score as a filter, but a response can be non-toxic and still terrible.
All this leads to an inescapable conclusion: initial- and ongoing-testing are good things. But how? In this post, I’m going to introduce an approach to testing using a less well know aspect of LLMs called “embeddings” which allow you to compare two outputs for a semantic similarity: do they say the same thing? This will allow us to see if the outputs from our LLM go off the rails either randomly or permanently (because of a new model version perhaps).

Pass all the tests with flying colors by subscribing!
What’s an Embedding?
I’ll start with an analogy: JPEG images. If you take a photo and save it in PNG format, the image stored in the PNG file is exactly what you put into it. But if you save the image into JPEG (or .JPG) format, the image is simplified in a way that hopefully looks the same but takes less space. Here’s an example using a photo of a flowering thistle plant we spotted along the Northern California coast...


You can see that the JPG file isn’t as good as the PNG. On the other hand, it’s 1/50th of the size and is recognizably the same photo.
Embeddings are similar in that they take a block of text and reduce the size dramatically by keeping the meaning of the text while losing the precise wording. The similarity stops there, however, as they don’t reduce it to some more compact text; instead, they reduce it to an array of numbers called a vector2. And that array of numbers has a very interesting property: if you take two vectors and compare them3, how “close” they are indicates how similar their meanings are.
Example
I have a Google Colab notebook that demonstrates this concept simply. You’ll need an OpenAI API key to run it. If you don’t, they’re easy to get; I have a page in this Substack that will get you going:
Quick Start with OpenAI and Salesforce
If you’ve joined in with us recently, you may not have all the tools you need to follow along with the projects. This page will get you ready. 0. Subscribe and Share If you’re here, and you’re not a subscriber, fix that first! If you are a subscriber, please
When you do, open the notebook:
The Python code has the following sections:
Importing all the libraries it needs
Inputting your OpenAI API key
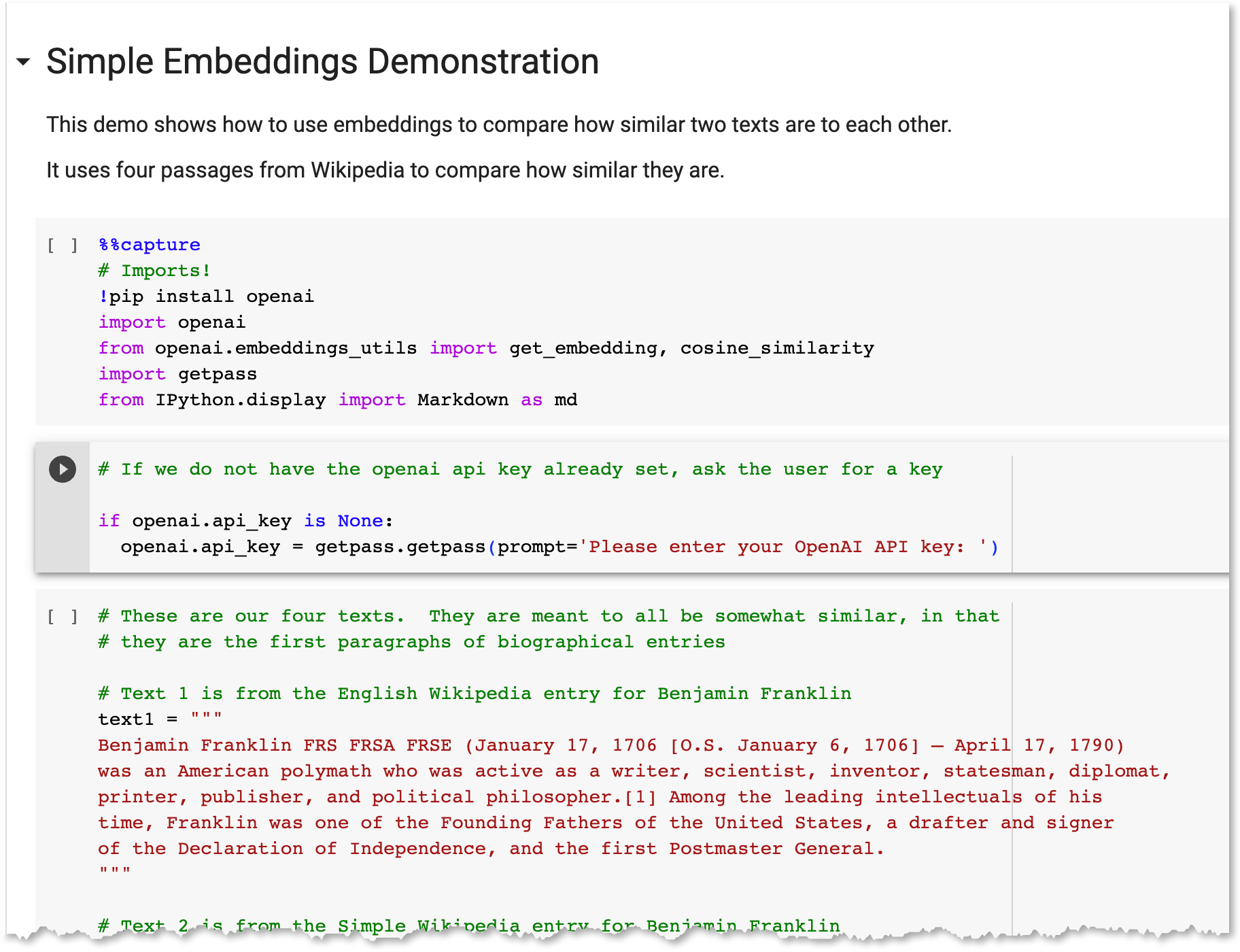
Setting the four blocks of text we’ll use. Each was taken from Wikipedia, and they are the first paragraph of the entries for Ben Franklin, Ben Franklin but from the Simple English Wikipedia, George Washington, and Kahn Noonien Singh (of Star Trek fame).
Calling the OpenAI embedding API on each text:

Computing the Cosine Similarity between all the embeddings:

Displaying the results in a table


When it runs (Pick Runtime → Run all from the menu), you’ll see a table like this at the end:

You can see that the two biographical entries for Ben Franklin are fairly close, while Kahn is the most unlike the rest4.
This is how we’ll look at the outputs of an LLM: create an embedding of the output and compare it against our pre-validated outputs.
Looking Ahead
On Tuesday I asked “If it works once, are you done?” The answer is most definitely no, and you should be wary of approaches that let you assemble a prompt, get it to work once, and then deploy it. This is still software development whose rules still apply: prompts that worked once in a sandbox need to be thoroughly tested in a realistic test environment before going to production.
Next week, we’re going to look at how to put together a simple test running application that will verify that our prompts are generating consistent outputs. It won’t be sophisticated, but it will allow you to verify that you’re getting (or still getting) the outputs you expect.
You won’t test our friendships if you share this…
Off Topic
Thistle has aggressive thorns but is amazingly beautiful. I can see why it’s the national flower of Scotland:




Another substack writer just noted this aspect of OpenAI regularly updating their models:
Behavior drift makes it hard to build reliable products on top of LLM APIs
[…] Given the nondeterministic nature of LLMs, it takes a lot of work to discover these strategies and arrive at a workflow that is well suited for a particular application. So when there is a behavior drift, those workflows might stop working. […] It is little comfort to a frustrated ChatGPT user to be told that the capabilities they need still exist, but now require new prompting strategies to elicit. This is especially true for applications built on top of the GPT API. Code that is deployed to users might simply break if the model underneath changes its behavior.
The size of the array varies from model to model; somewhere in the range between 256 and 2048 is very common. The important thing is that the vector is fixed size for any model, so if your model returns an array of length 512 for one input, it returns that sized vectors for every input. If your text is quite short, you may find that the embedding is larger than your text; the PNG vs JPG analogy wasn’t really about compression per se as about creating a another version of something that still has some notion of being “the same”.
The comparison is either via a dot product if you’ve normalized the vectors or a cosine similarity if you haven’t. Either way, it’s super quick to calculate (especially if you have a GPU).
Although Kahn is a bit more like Ben Franklin than George Washington, which I can see…