


Let's Put Free LLMs to Work
I'd quip that we want to beat it like a rented mule, but Mule as a Service is very not free

Last week, I suggested you install Ollama and give it a whirl:

If you’e done that, you might have thought “nice parlor trick,” and you’re most certainly right.1 But Ollama has a secret trick up its sleeve2: an API server that allows you to make calls from other applications.
Hmmm, what can we do with that? Anything useful?3
Let’s look at a simple Python application to exercise Ollama’s API and see if we can draw any interesting conclusions. Perhaps I can even convince you that in a few years, what seems like a bit of a toy today will turn out to be quite important.
First, though, a confession.
I didn’t write the application I’m about to share with you. ChatGPT did, or at least the first draft of it (there was a lot of fit and finish work I did). Honestly, it would be insane these days to write code from scratch. Building web apps is extremely verbose and unproductive. How much work do you have to do to build a simple set of radio buttons?
<input type="radio" id="red" name="color" value="red" onchange="changeColor()">
<label for="red">Red</label><br>
<input type="radio" id="blue" name="color" value="blue" onchange="changeColor()">
<label for="blue">Blue</label><br>
<input type="radio" id="yellow" name="color" value="yellow" onchange="changeColor()">
<label for="yellow">Yellow</label><br>Or, you can write:
I want HTML radio buttons with the primary colors that will invoke a function called "changeColor()" when the color is changed.If you wonder why Salesforce’s OmniScript has hung on so well despite so many people wanting to kill it that you’d think Shakespeare wrote a play about it, it’s because it is several orders of magnitude easier than building a custom LWC.
ChatGPT is free.4 I assume OpenAI has its reasons. And yet I find it better at creating an app from scratch than GitHub’s CoPilot5, which is much better at snippets of code, IMHO.
It’s a bit harder than just typing in a few lines of text, but it’s so much easier than writing the code from scratch. I don’t know how many of you would find the precise process I followed interesting, but I created a post with a lightly annotated transcript of that session so you can see how I did it:
How I used ChatGPT 4 to Build an App for Me.

This is not a normal post. I’m going to walk you through the chat session I had with ChatGPT 4 to create the Ollama sample app. It’s going to be mostly a transcript of the session with some annotations. I did not expect it to build the final “production” version of the app. Rather, I wanted to avoid all the monotony of building the UI and API interf…
If you find that useful or interesting, leave a comment on it and let me know?
Back to the main topic…
The App
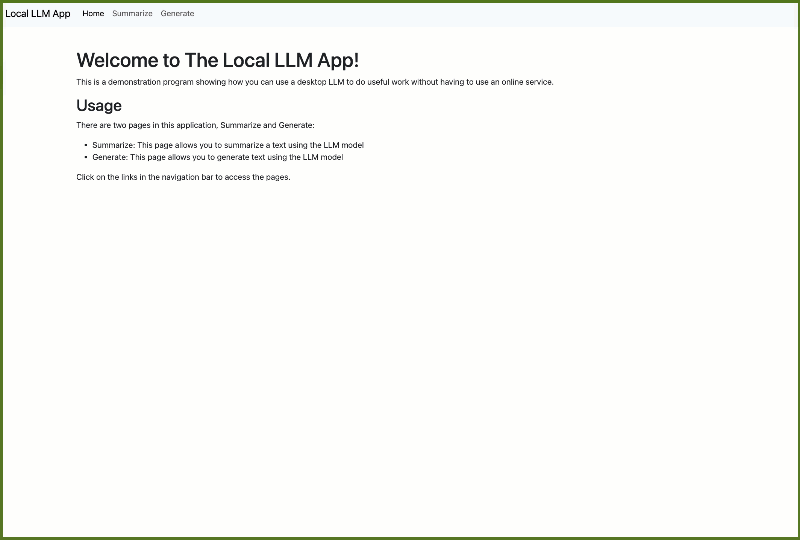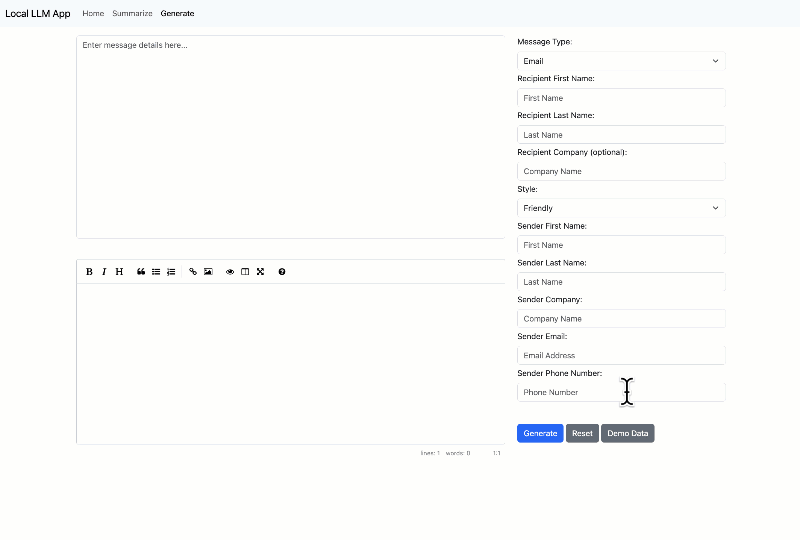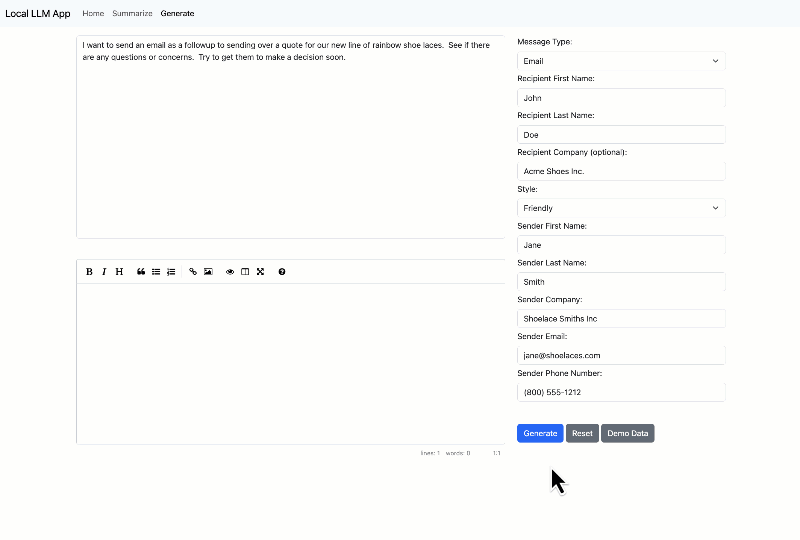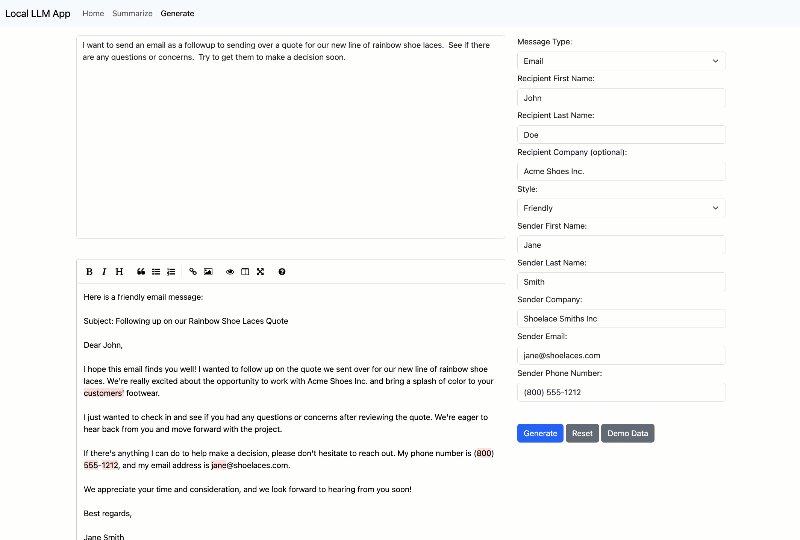
First, let me show you6 the app working. I’ll start with summarization:
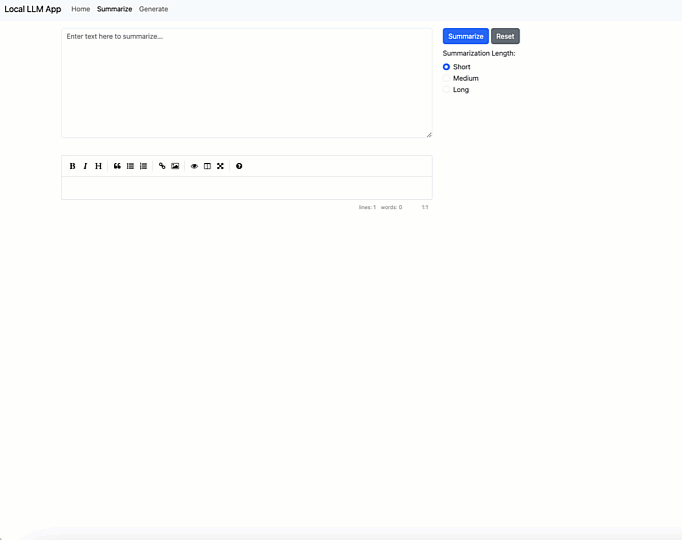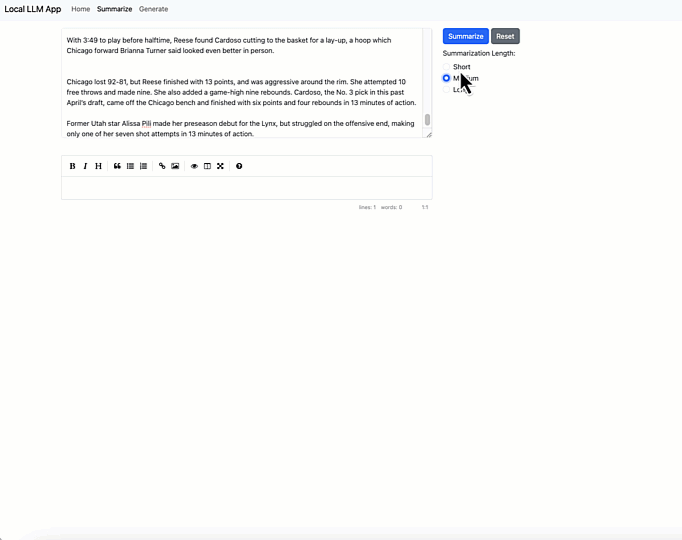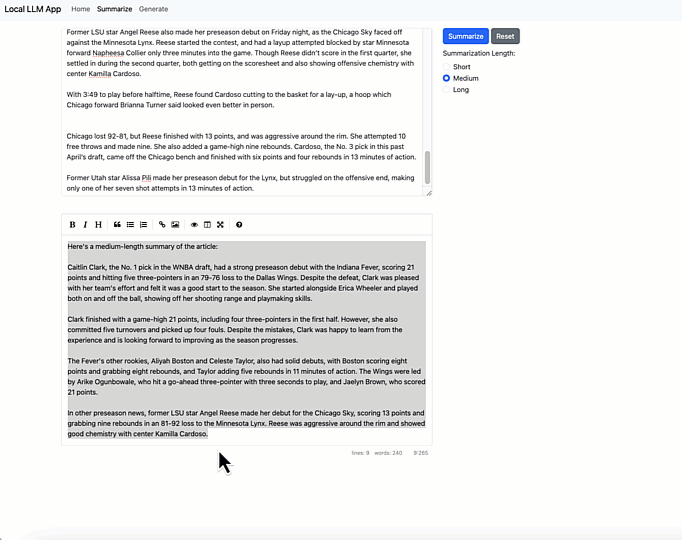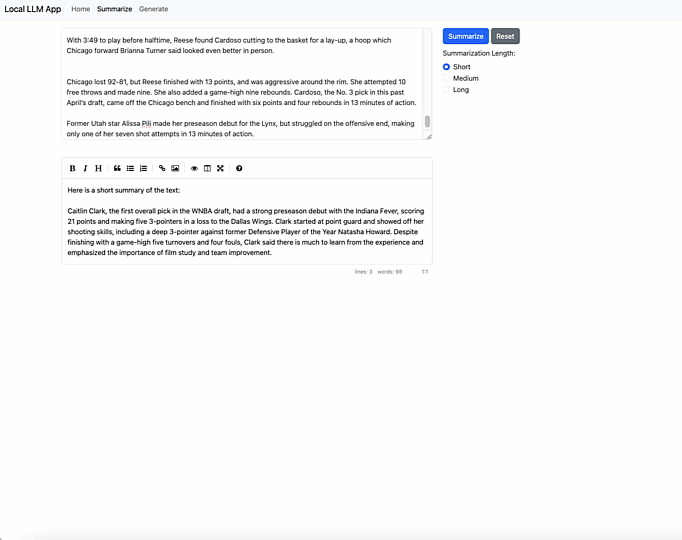
It’s pretty simple: paste in a long text document, choose your summarization length, and have a summary generated.
The other capability is generation:
To run this you’re going to need to have python installed. As always, Anaconda is a decent place to get a well managed environment. Then you can clone the repository with the code:
https://github.com/cmcguinness/LocalLLMDemo
The README.md has the latest installation and usage instructions. Make sure you have Ollama running before you start.
Is this Important? Is it Interesting? Do you care?
When I run Ollama with Llama3 8B (which is about 5GB in size) on my M2 Pro powered 32GB Mac Mini, it performs well, because Apple has invested in AI/GPU cores in its processors. But when I try to run Llama3 70B, it hits the wall because my Mac runs out of memory.
There are two solutions here: smaller good models, or more memory. Pop-quiz: When has software ever gotten smaller over the long run. Never, right? So, more memory it is.
That’s why I think, in a few years, there’s going to be a real need for a huge refresh of desktop and laptop computers to get systems that are built for AI. That refresh is going to involve two things: (1) More AI cores (of whatever variety) and (2) A lot more memory. Although the local LLMs we’re playing with today clock in around 4 GB in size, more functional ones (like Llama3 70B) come in around 40GB.7 To run them, you’re probably going to need 64 GB of ram to go with that more powerful GPU/AI core. People have complained that Apple’s base line configuration for low-end Macs is 8GB of RAM8 for a while now. I agree: I don’t see how Apple can square its AI ambitions with such a stingy amount of RAM.
As these upgrades start to happen, we’re going to see more and more apps with embedded LLM capabilities. Not that use services in the cloud, but that run locally. Why? Not for any technical reasons per se, but because personal productivity apps have a very hard time trying to charge on consumption. That’s why the “consumer” ChatGPT+ is $20/month9, but the GPT API is priced purely by consumption. But if you can run an LLM locally on the PC, there’s no marginal cost to calling the LLM, and a fixed subscription charge for software won’t raise concern about usage levels.10
If you want an example of where this could be truly amazing, imagine a Microsoft Edge browser that incorporates a local Microsoft LLM engine.11 Your web apps (or local apps using the browser) could consume all the LLM services they want without extra costs. Or imagine a version of MacOS with an Apple supported and optimized LLM engine which is available to all native Mac apps.
In some ways, this is reminiscent of the whole PC movement of the 70s and 80s — putting compute power on people’s desktops. Before that you had terminals that were connected to mainframe or minicomputers in an arrangement called “timeshare”. The timeshare approach didn’t really go away, the terminals just turned into browsers and it all got rebranded as “Software as a Service”: old wine was poured into new bottles.
Of course, I have no doubt that for the foreseeable future, there will be a viable market for LLM services in the cloud that support the largest of models running on the most performant of hardware. But we are → ← close to being able to run decent models on desktop and laptop computers. After that, everywhere. When that happens, it’s going to be wild.
Mostly because parlor tricks are impressive to most people, and after demonstrating the somewhat sluggish LLM running on my aging MacBook Air to my wife, I learned this is definitely not impressive to most people. Yet.
Not actually secret
If you have a Snidely Whiplash mustache, feel free to twirl it at this point.
Disclaimer: not to OpenAI to run, and the better version of ChatGPT is $20/month, but still, 3.5 isn’t that bad. In my linked article, I used ChatGPT 4 because I do pay for the $20 service (so I might as well get value for my money), but I tested with 3.5 and it works fine for this task.
I suppose other CoPilots could be better, but I’m not spending my time in potayto-potahto bake-offs.
This is inside baseball, but I use Camtasia to capture and then edit the demo, and then export it as an animated GIF. That is the only format I’ve found that works reliably in Substack and presentations to just effortlessly loop through a video. While is asinine, but that’s the state of software today.
I have no doubt that smaller, more focused models will become available at a variety of sizes as time goes on, but right now it feels like a 5GB model (the smaller llama 3) is too small as it makes factual errors (my favorite test prompt is “who was the 20th president of the USA and what is he most famous for?”, which the 4.7GB llama3:8b answers by saying James Garfield and that he was the first president who was assassinated (eh no, he was the 2nd)), and a ~10GB model, were one to exist, would be a lot better. Microsoft’s 2.3GB Phi3 feels like the Chihuahua of models: too much dog with too little of a head to make any sense.
And their upper limits are low as well; MacBook Airs, 14-inch MacBook Pros and iMacs top out at 24GB and Mac Minis at 32GB. If you want 64GB, you have to spend $2400 for a Mac Studio or $4000 for a 16-inch MacBook Pro. I’m not saying everyone needs 64GB of memory, just that Apple is going to have to stop being so damn stingy with RAM, because 16GB is going to be the bare minimum of what people need.
With limiters, so you can’t abuse it.
Note that this does NOT apply to enterprise software, which requires more sophisticated pricing.
Google should be the first one to do this, but does their thirst for getting access to their users’ data keep them tied to a server based offering? I think the answer will be yes until they start to lose their users to eg Microsoft (and therefore Bing).
To me, the touching point is when you mention OmniScript. Nevertheless I am afraid AI will soon put it out of business, in that creating a custom LWC will be similar to your creating the Demo App.