

Intro
Last week I discussed the impact of Meta releasing its large, 405 billion parameter, LLM, Llama 3.1 405B, to the wild – free for anyone to use. At the same time that it released the 405B model, Meta updated Llama’s two smaller models, a 70 billion parameter one and an 8 billion parameter one. The question is: is there anything really new about them, or are they just tweaked versions of v3?
It turns out, there is something(s) new!
Even the 8 billion parameter model now has a 128K (token) context window. This means you can shove about 512K (bytes) of text at it and it can make sense of it.
Although the number of parameters is small, the amount of training (15 trillion tokens) that went into Llama 3.1 is large1, and so long as you don’t exceed its limits it does really well.
Because Meta allows anyone to run these models for free (on their own hardware), there’s burgeoning competition from hosting companies, which results in low prices for these large context window models. One hoster, DeepInfra.com, charges 6¢ per million tokens (for both input and output). If you can keep your context window below 8K, Both HuggingFace and Groq2 charge 0¢ per million — that is, free.
Whatever can we do with this dirt cheap AI? Hmmm….
An Example Use of Dirt Cheap AI
Let me give you an example to demonstrate how all of these things, together, make for a very good but dirt cheap to run application. The application I’ll demonstrate is one that generates summaries of the content of YouTube videos.
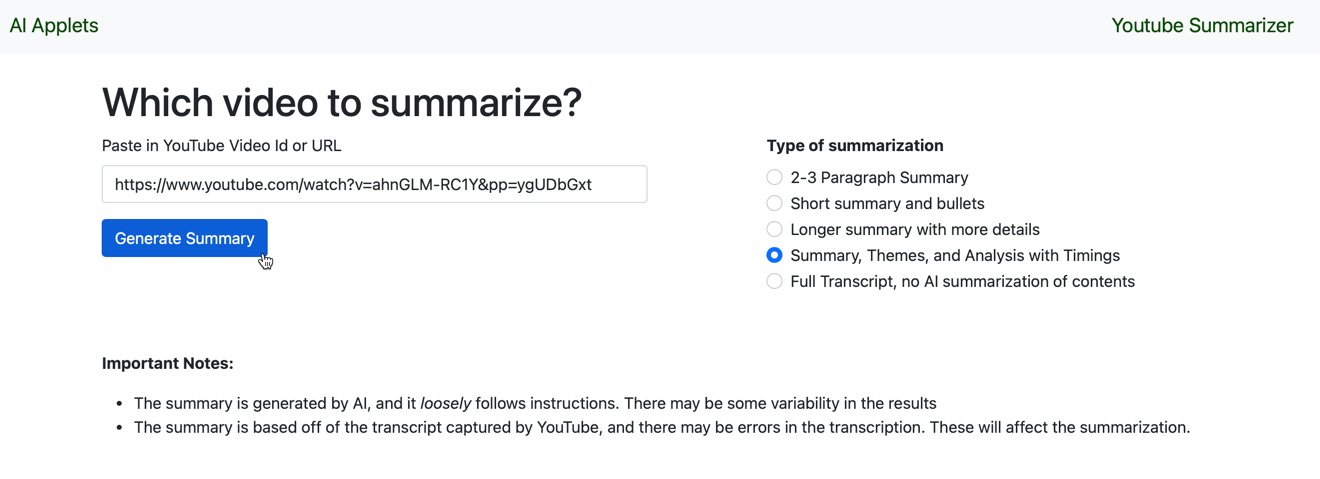
Just copy the link from a video of interest (and this one is a very interesting video):

Paste it into the app, choose the length of the summary:
Wait a few moments for the AI Hamsters to spin up the wheel and grind through the text:

And you get a summary with the level of detail you asked for.
Want to try it yourself? Because it’s so cheap (less than a tenth of a cent per video), I’m going to open up the app to all of you — at least for a while3. Go to:
And select “Run Applet” for the one and only (for now) example on the page.
Use the user id of “demo” and a password of “demo#user”. Be kind, don’t share the credentials with anyone (make them subscribe to this blog first :-) ). If you actually find you like using it, let me set you up with your own login: just shoot me a request.
Backstory
I don’t know about you, but there are far more videos I want to watch than I have time for. And a lot of the videos turn out to be duds – or just spend forever getting to the point.
If you’re like me, you end up playing videos at 2x (or faster if you google the hack for that). But that gets tiring. What I really want is a short summary of what’s actually discussed so that I can decide if it’s worth watching. And that’s where this app comes in. Because the services for Llama 3.1 8B are so cheap, it costs me almost nothing make a summary.
Run It Yourself!
Before I dive into the design, might you want to download the sources and play with it yourself?
https://github.com/cmcguinness/YoutubeSummary
The README.md has instructions on getting it to work.
You say: So What?
Ah, a fan of Miles, I see…
There’s nothing unique about summarizing text, it’s one of the core abilities of LLMs. Getting the prompts right to generate specific formats only requires a soupçon of prompt engineering.
The “so what” is the idea of doing some sort of useful, timesaving transformation of data that benefits the users. In this case, it’s summarizing a transcript from a YouTube video, a feature which YouTube doesn’t provide themselves. You can do it by hand (in fact, I did, which is why this app came to mind), but it’s awkward and slow. The app isa great way to work through a backlog of videos quickly, allowing you to optimize where you pay attention4.
Sure …. it’s nowhere near a start-up level idea, but there’s a lot of good ideas out there that aren’t “startup fodder” but are nonetheless valuable.
Let me give you another example: how about an AI service that could process your email, discard the junk, provide classifications and short summaries of the stuff that is iffy, and sort the important email for you? Something like5:

Or…

With 128k context window and ultra-cheap costs, Llama 3.1 8B can classify almost all email accurately for less than 1/10th of a cent each (the first one cost $0.0004, or 0.04 cents). The magic is not in the prompt, it’s in writing all the code to integrate with the email server and manage the influx of mail.
In the next post, I’ll talk a bit about how the code for the YouTube summarizer is architected. There’s some interesting lessons in there.
To be fair, Llama 3 was trained on 15 million tokens as well.
Groq is not Grok: Grok is Elon Musk’s AI company (aka xAI).
I’ve set about a $20 shutoff point in LLM charges, which would translate to roughly 20,000 transcripts per month. If it gets anywhere near that, I’ve got trouble, right here in River City, and that starts with T which rhymes with P, and that stands for popularity. Or something like that.
Kind of a meta-pun about LLMs.
If you’re wondering what I have, it’s a hacked together barely running prototype that feeds the raw email to Llama 3.1 8B with the prompt:
Below is an email I received.
You will do the following:
1. Summarize its contents in one sentence.
2. Determine which of these categories it falls into:
1. **Junk**: Spam, Phishing, Political Fundraising, Advertising
2. **Important**: Real Bills, Updates on Product Orders, Shipping Status, News and Blogs, Personal Emails, Work Emails
3. **Questionable**: Stuff that falls between the two.
3. For the **Junk**, you will output "Junk Email, No Need to Read"
4. For the **Questionable**, you will indicate that the email is questionable, and write a one paragraph summary.
5. For the **Important**, you will indicate that the email is important as well as a description of why.
If you detect signs of phishing, you should err on the side of calling it **Junk**.
I did not invest a lot of time in this. The real work would be in plugging into a mail server to automatically process the incoming emails. Integration is always hard.
Keep the predictions coming, O Wise One! The cost of AI overall is fast approaching free as you predicted.