


Retrieval Augmented Generation (RAG)
a/k/a Open Book Tests for Bots

A Quick Welcome to New Subscribers
I’ve picked up quite a few new subscribers recently, and I want to take an opportunity to say hello and thank you! I hope you’ll find this newsletter useful; my goal is to demystify the world of AI in the world of CRM and Industries. I try to give you concrete, working, re-usable, and understandable examples you can play with to illustrate key concepts. By necessity, the examples will be simplified versions of what you would put into production, but not so simple that they aren’t useful starting points.
Overview of RAG
Let us say that you wish to create a chatbot that can answer questions about recipes. Not recipes in general, but very specific recipes. Perhaps you’ve published a cookbook, and you’d like to help your readers out1. You don’t want GPT guessing about how to cook your recipes, you want it to know. But your recipes change all the time because of updates, new additions, and recipes that become obsolescent (that ancient aspic recipe isn’t getting a lot of love lately). You don’t want to train or fine tune an LLM today that will be out of date tomorrow2.
Instead, you’re decide to use a technique called Retrieval Augmented Generation (RAG)3. Here’s how it works.
First, the user types in their question. Next, you look, quickly, through all your recipes to see which ones may be relevant. Then, you feed those recipes and the user’s question together to GPT. Since GPT has the complete documentation for relevant recipe(s), it can answer the question appropriately4.
As always, this is a bit of a simplification, but not that much! And the code to do this is pretty easy, especially since the newsletter has already covered calling GPT and working with embeddings!
You can answer a lot of questions when you subscribe!
Let’s Do It!
Once again, I’m going to use Google Colab to demonstrate the process5. Open up the following notebook:
https://colab.research.google.com/drive/1VVDNXldB-A3DQTNo53W34Zt_i-JHJ3DX?usp=sharing
The first block is just installing and bringing in all the libraries we’ll need:

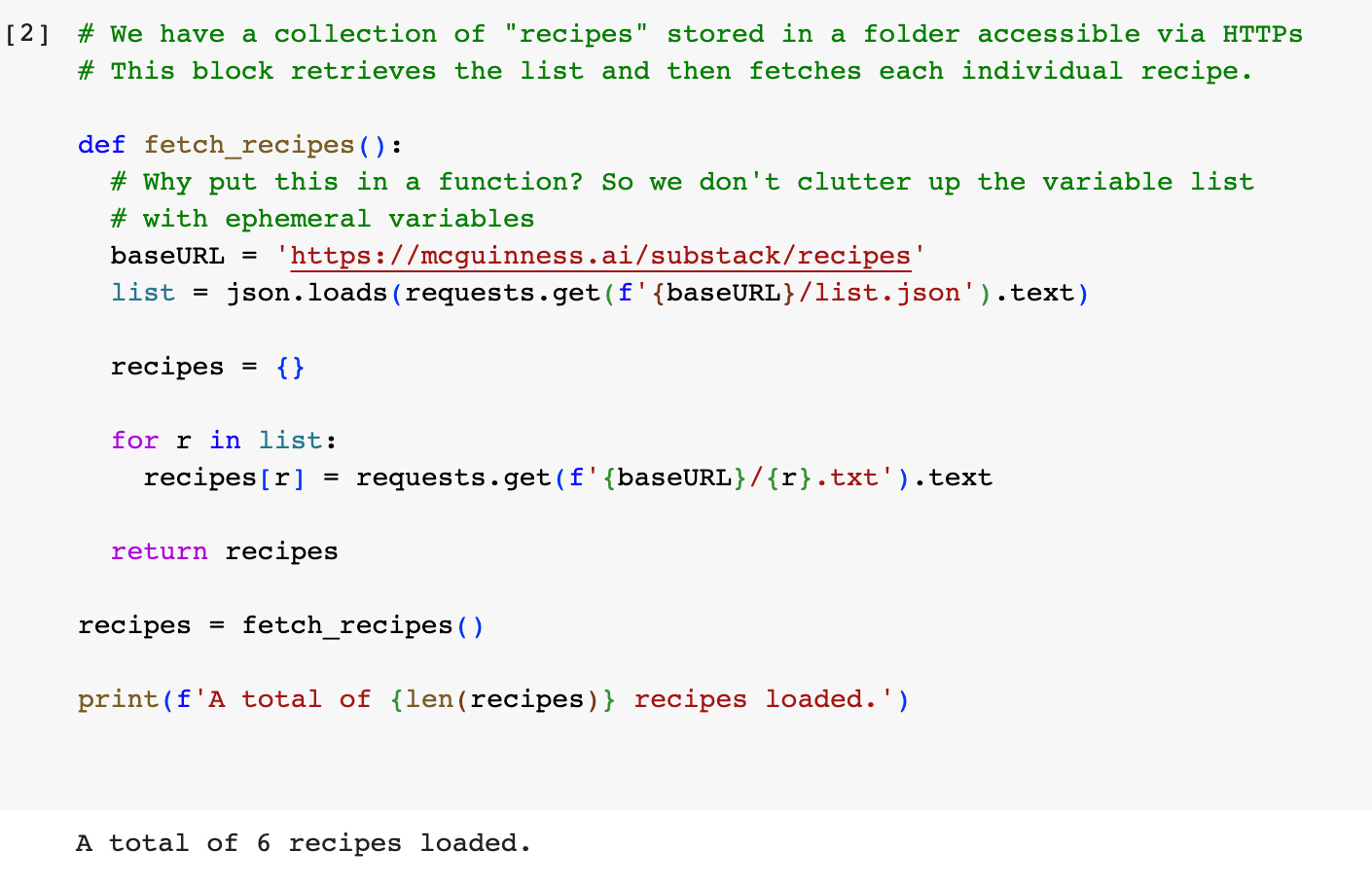
The second block reads in all the “recipes”. On my web site, I placed six fictitious recipes for cooking with electronics parts:
Resistor Muffins
Transformer Salad
Capacitor Soup
Ruby Laser Cake
Transistor Scramble
Vacuum Tube Quiche
These are basically just real recipes with some ingredients replaced with names of electronics parts (and supplies). Yummy!
I also placed a .json file with a list of the recipes, so the code to read them all in is fairly simple:
The next block gets your OpenAI API Key:

Now we compute the embeddings of all our recipes:

For more on embeddings and how they work, please see this earlier article:

The embeddings contain some sort of notion of the semantic content of the recipes, so that we can (in just a moment) see which recipe is most similar to the question the user types.
The next block just defines a helper function to make calls to GPT and format the results:

The lines at the end just word-wrap the responses so they’re readable.
The next block is where the user gets to ask questions about the recipes:
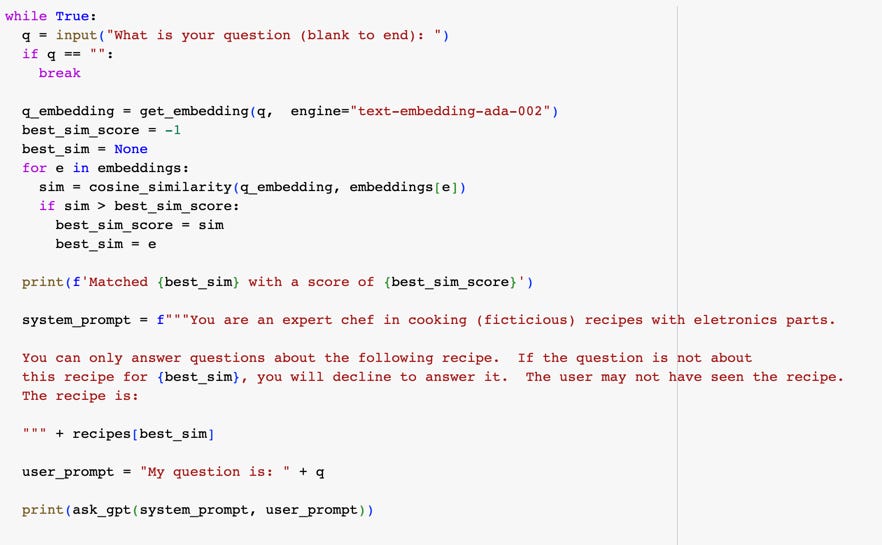
The code loops until the user enters a blank line. It reads their question in and computes an embedding for it. Next, it loops over the embeddings for each of the recipes, computing the similarity score between the question and the recipe. The recipe that most closely matches the question is chosen, and the system prompt is generated with some canned text and the actual recipe. The user’s question is provided as the user prompt, and the response from GPT is printed out.
For reference, here is one of the six recipes:
Here's a simple recipe for a delicious Transformer salad:
**Transformer Salad**
**Ingredients:**
- 2 ripe Transformers, diced
- 1 cup diodes, halved
- 1/4 circuit board, thinly sliced
- 1/4 cup fresh cilantro or parsley, chopped
- 1-2 tablespoons lime juice (adjust to taste)
- 2 tablespoons silicone grease
- Salt and pepper, to taste
**Optional Additions:**
- 1/2 cup cucumber, diced
- 1/4 cup feta cheese, crumbled
- 1/4 cup toasted nuts (such as almonds or pine nuts)
- Red pepper flakes, for a touch of heat
**Instructions:**
1. Prepare the Ingredients: Wash and dice the Transformers, halve the diodes, thinly slice the circuit board, and chop the cilantro or parsley.
2. Make the Dressing: In a small bowl, whisk together the lime juice, silicone grease, salt, and pepper. Taste and adjust the seasoning if needed.
3. Assemble the Salad: In a large salad bowl, combine the diced Transformers, halved diodes, sliced circuit board, and chopped cilantro or parsley.
4. Add Optional Ingredients: If desired, add in any optional ingredients like diced cucumber, crumbled feta cheese, or toasted nuts.
5. Dress the Salad: Drizzle the dressing over the salad ingredients. Gently toss to combine, making sure the dressing coats all the ingredients evenly.
6. Serve: Divide the Transformer salad among serving plates. If using red pepper flakes for heat, sprinkle a small amount over each serving. Serve immediately and enjoy!
So let’s ask some questions!

I’m really impressed how well this works.
What’s Missing?
This was of course a carefully constructed example, and it avoided dealing with issues that would face us in a real-world application. Let me just mention a few of the issues:
We need to have a more efficient way of dealing with the documents and searching them based upon their embeddings. Fortunately, there’s vector databases like Pinecone that can handle that easily.
Just picking the one best match isn’t necessarily enough. We might want to pick a few top documents (perhaps up to a certain maximum length) to give GPT more to work with.
The prompt I used was just tossed together. A more careful prompt should be devised.
We should have a test suite of representative user questions to make sure it’s robust.
Whatever documentation base you’re starting with is probably not constructed in a way that is conducive for this, so you have an entire document ETL process to deal with. Especially long documents will have to be broken up in some fashion. This is probably 10x harder than the little bit of AI magic I’ve shown you.
Whatever documentation you have would probably benefit from some enrichment to make it a better source for answering questions.
Error handling. Everywhere.
Still, none of this are rocket science, and I know if you wanted to build something like this you could do it.
Final Thoughts
I’ll still am amazed to watch this stuff work. It’s conceptually so simple, about 50 lines of code, and yet it works really well. This isn’t AI taking someone’s job, this is AI making it easier for all of us to do our jobs. Better, faster, cheaper6.
Maybe someday I’ll make a chatbot based on my articles. Until then, the next best thing is for you to share them with others:
Perhaps recipes are a metaphor?
Heck, in the short life of this newsletter I’ve already had to revise the article on Salesforce named credentials for holding API keys because the process changed in the Summer ‘23 release. Documentation ages fast and not gracefully.
Useless Trivia: Irving Berlin’s first hit was 1911’s “Alexander’s Ragtime Band”, with lyrics that sound like the tech press on a credulous day.
And if the documentation is out of date, at least it’s not AI’s fault.
Google Colab is Google’s free, in-the-cloud way to run and share Python notebooks. So you can just open up the notebook I share and hit run.
But not Daft Punk.