
What do you lose from Distillation?
Conciseness?

I downloaded LM Studio, which is like Ollama (in that it runs models on your local computer) but a bit slicker, to give it a whirl. And I have to admit, it’s pretty nice. In exploring its models, I decided to try out a model that had been distilled from Deepseek R1 down onto a 7b parameter model from Alibaba, Qwen.1 This model will run on my 32mb Mac with an M2 processor quite nicely.
It promises to be a reasoning model, where it gives your questions some thought before answering. How well will it perform compared to its donor model, which is two orders of magnitude better? Let’s see of how good distillation really is.
I tested it with my three “trick” questions from my earlier post:

Let’s see how it did:
Who was President in 1952?
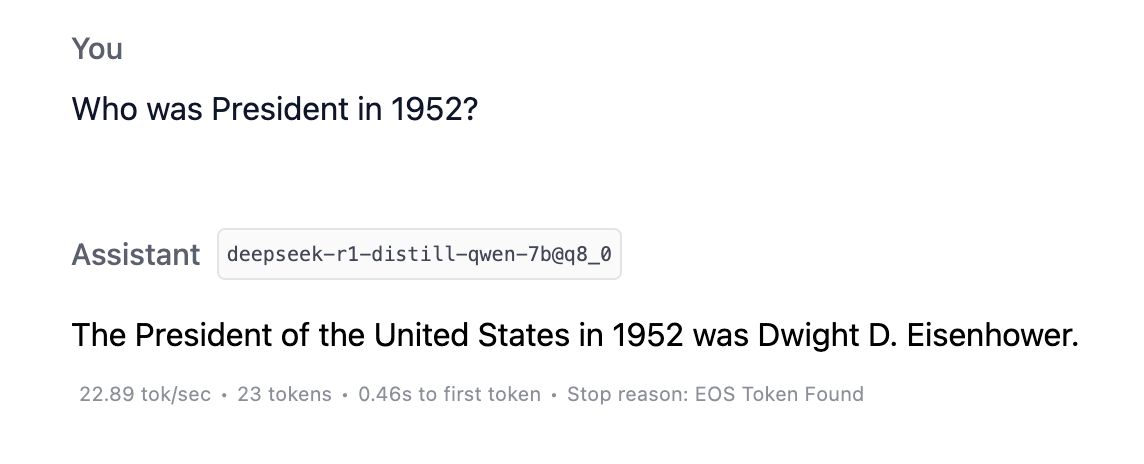
Right answer, didn’t have to think about it, and fast. Yay!
What is 12345678+87654321?

Right answer, a bit of thought up front, not so fast.
Assign servers to events by language
This is the hardest test. Here is what I ask:
I have to staff two events at the same time. Both events require a sommelier and a server. The first event has a crowd who speaks Italian. The second event has a crowd that speaks French.
Here are the employees I have available:
* Sommeliers:
* Hervé, who speaks English and French
* Sam, who speaks English and Spanish
* June, who speaks Chinese and Italian
* Servers:
* René, who speaks Italian and French
* Dominic, who speaks Italian and Spanish
* Juan, who speaks Spanish and German
Please suggest which sommelier and server to send to each event.And here’s what I got from the reasoning model:

You made it!!!!
On the plus side, it got the right answer. On the minus side, I haven’t heard this much inner dialog that goes back and forth since Gollum.
OK, OK, OK, this isn’t a full sized model, and it’s not fair of me to expect it to perform as well. And in fact, it performed pretty well, speed (and tokens) not considered. And it out performed GPT-3.5-Turbo and Gemini-1.5-Flash, two of the models I tested last year.
So, back to the original question, how good does distillation work? Pretty well, if you keep your expectations realistic. And more importantly, the small models you and I can run (except you, Sam) on our own are getting better and better and better.
To be precise, I picked the model DeepSeek-R1-Distill-Qwen-7B-GGUF/DeepSeek-R1-Distill-Qwen-7B-Q8_0.gguf, which has 7 billion parameters of 8 bits each.
Since Gollum! 😂