


Cracking Open the YouTube Summarizer
Why is it so busy in there?

My last post introduced the YouTube Summarizer AI App and gave you a link to run it as well as the source code. But even if you’re not interested in the code per se, there’s still a lot it can tell us about working with LLMs. Let’s take a look?
You can bring up the code at:
https://github.com/cmcguinness/YoutubeSummary
Some Opening Questions
As I walk through the design, I think there are a few things worth pondering1:
The structure — and amount — of the code. I don’t pretend it’s the very model of a modern
major general2 AI architecture, but hopefully it’s easy enough to follow along to give a sense for the tasks required to do this, and the relative complexity of each task. What is harder: getting a transcript from YouTube, or getting AI to produce a summary?A sense for how complicated of a task is being put to Llama 3.1 8B. LLMs generally get called on to do two things: To know things, and to know how to do things. What does the code expect from the baby Llama3? How good is it at meeting those expectations?
What would it be like if we swapped out GPT-4o, the (maybe?) most powerful LLM instead of LLama 3.1 8B, a very small LLM? We’d expect it to be better, for sure, but is it better enough to justify the expense4?
What other kinds of applications are there that following this pattern of sucking data out of another system, transforming it lightly, and then asking AI to do something with it are there? Anything ideas to mind?
So let’s walk through the architecture first and then see if we can answer the questions.
Overall Architecture
What are we dealing with here?
There are about 500 lines of python code (that has a lot of comments in it)
There are 78 lines of prompts, but there are separate prompts for each of the 4 types of summarization that have a lot of redundancy. It’s fairly light prompt engineering.
Python code tends to be a bit fluffy, like pancake batter with too much baking powder, so 500 lines is really not that big.
How is the code structured?
There are really three main parts of the application:
The User Interface to collect the URL and, later, show the results
The code that fetches the transcript from YouTube
The code that runs it through the LLM to generate the summary
User Interface
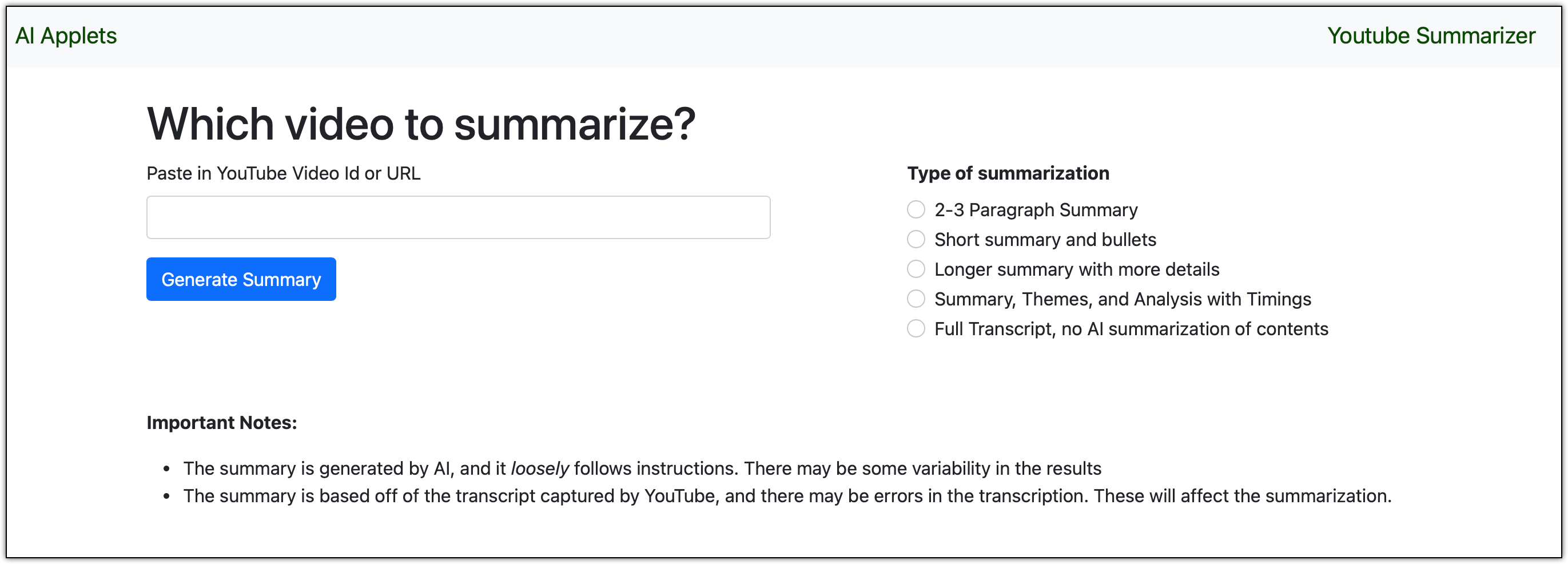
“Brilliant” … “State of the Art” … “Bravo!”
These things were never said about my UI skills.
Here’s exactly how I created the UI:
I want to build an app in python, flask, and bootstrap 5. It will have two pages. The first page will ask the user for a text input, labeled "Youtube Video Id". It will have a set of radio buttons that are driven by data from the server (variable list). The second page will display dynamically generated text content. Both pages will have a title bar across the top. Please give me the source of this app.I just fed this into ChatGPT and went from there. Like Thomas Kinkade, I just added a few “points of light” to finish it off.
So, if it looks like a simplistic, boiler-plate UI … Yepper! It sure is!
The UI code itself is about 100 lines of Python and also about 100 lines of HTML.
Fetching Transcripts from YouTube
Well, um, er, there really isn’t an API to do this, so please keep this quiet, OK?
There are three things I do here:
Extract the Id of the video from the URL.
Get the title of the video, which I do just by fetching the page and finding the title tag.
Retrieving the transcript of the video.
For #1, It turns out there’s a few different formats for YouTube URLs, so I have to do a bit of string manipulation to figure out which format the user gave me and then to extract the ID.
For #2, the code is very simple:
def get_title(video_id):
video_id = get_id(video_id)
try:
r = requests.request('GET', f"http://www.youtube.com/watch?v={video_id}")
except requests.HTTPError:
raise YouTubeError
if r.status_code != 200:
raise YouTubeError
page = r.text
title_start = page.find('<title>')
title_end = page.find('</title>')
title = page[title_start + 7:title_end]
if title.endswith(' - YouTube'):
title = title[:-10].strip()
return title
Not even worth using a true HTML parser.
For #3, ah, well, there’s a bit of magic: there’s a python package someone published to extract the transcript, so I can just call it:
def get_transcript(video_id):
video_id = get_id(video_id)
try:
transcript = youtube_transcript_api.YouTubeTranscriptApi.get_transcript(video_id)
except youtube_transcript_api.NoTranscriptFound:
raise YouTubeError
full_text = f'# Transcript of "{get_title(video_id)}"\n\n'
for t in transcript:
full_text += f"[{secs2string(t['start'])}] - {t['text']} <br>\n"
return full_textIt returns an array of objects with the start time, end time, and text for each snippet of the transcript. I just convert them into a very long string, with the title at the top (the title actually helps the LLM make a better summary!).
It’s not really a massive amount of code, but that’s probably because I was able to get a lot of the heavy lifting done with a library. Regardless, the key point is the code is responsible for chasing down the video, extracting the transcript, and formatting it properly for the AI work to follow.
The code to extract the YouTube data is about 100 lines (there’s a pattern developing here, isn’t there?)
Generating the Summary
Unless you opt for the full transcript, the next step in the process is to ask the LLM to summarize the content.
The application code supports one of three different LLM engines:
OpenAI (presumably, GPT-4o-mini)
DeepInfra (to use Llama 3.1 8B)
Ollama (to use something on your desktop)
Regardless of which you pick, there is one common system prompt, and 4 different but similar user prompts to generate the various levels of detail in the summary.
Here’s a typical prompt:
Please provide an approximately 800 to 1200 word-long analysis of the transcript below from YouTube.
It will be structured as:
* **Topics**: a 1 paragraph high level summary of the discussion.
* **Summary**: Summarizes the content of the transcript with a few paragraphs details the topics that were discussed. The goal is to do this in 500 words.
* **Important Points**: Identifies the important points that were made in the transcript using two levels of bullet points to structure the section.
Make sure you capture the points made, not just the topics discussed.
The transcript is:
```text
{text}
```It’s pretty straightforward, but you could certainly augment it with more instructions on how to extract or format data for what you want to see.
There’s about 150 lines of code for this part, including the interfaces to the three different LLMs (only about … you guessed it … 100 lines if you only want code for one LLM). This is not unusual where you are doing a single LLM pass at some text; the interface to the LLM is not hard,
It would probably be about 50% more code if I had put in error handling, but for a demo it’s just going to assume that everything is working, more or less.
Miscellaneous
There’s a bit of fit and finish code and files as well.
If you look at the repository, you’ll notice the files requirements.txt and Procfile. Requirements just lists the libraries that the application uses (and version numbers). Procfile allows this to be run on a serverless environment like Heroku or Railway.
There’s a file md2html.py, which converts markdown (that LLMs like to generate) to HTML. Yes, there are libraries out there that will do that. For some reason, they choke badly on nested lists, which is deadly for this app. So I had to hack my own. It’s about … I’m getting repetitive … 100 lines of code.
Lessons from Code
What is harder: getting a transcript from YouTube or getting AI to produce a summary?
Turns out, they’re both about equally hard. Or equally easy.
How hard/easy is that?
Objectively, it’s not that much code. Experientially, I would say that getting the prompts just right was probably the hardest, because the process of refining the prompts consists of making a change, keeping it if better, reverting if not, and iterating a lot to get what I want.
It would be harder if either (or both) (a) the integration to get the raw data involved a lot more work. Perhaps the data comes from multiple places. Perhaps authentication is more complex. Perhaps the data comes back in XML and we want it in JSON. Lots of things could make it harder.
Also harder would be (b) We need to do more complex LLM work. Perhaps we need to do RAG (or its cousin, OpenAI’s assistants). Perhaps the prompt engineering leads us to one- or many-shot prompts. Perhaps we have to fine-tune the model.
What about using LangChain or some other AI workflow tool?
This problem I solved here wasn’t really sequencing the AI. It’s a sort of ETL problem that doesn’t need a workflow engine to run. If the complexity increased quite a bit, then a workflow tool starts to become more attractive.
What Are We Asking AI To Do?
You’ve seen the prompt above, it’s not complex. But what exactly am I expecting the LLM to do? It seems to me it needs to:
Read through the entire transcript
Produce a very short summary of what the theme of the video is.
It has to identify and decide what the major topics are in the transcript and summarize them.
Identify what the major points are that are being made for each topic.
Generate an output document with the right structure.
That’s a lot of work, and if you’ve run the demo, you can see it takes a while to complete.
How do I expect it to do this?
It’s important to differentiate between facts the LLM knows (who was the first president kind of facts) and processing the LLM knows how to do (reduce 1000 words to a 20 word summary).
The Llama 3.1 8B model doesn’t really have a big enough brain to “know” a lot of facts outright. So it’s going to hallucinate a lot more than the 405B model when you ask it for obscure facts. And YouTube videos are often full of obscure facts. If it’s a video from Veritasium, it’s really going to be obscure.
Fortunately, I’m not asking it to know obscure facts or anything about the topic in the video. It needs to understand what’s in the transcript, but it doesn’t need to know anything about it per se. I think this helps keep the problem tractable to the small LLM.
What about GPT-4o?
Here’s a summary generated by GPT-4o:

Here’s the summary produced by Llama 3.1 8B with the same video and the same prompts:

GPT-4o definitely did nicer formatting. It also generated slightly more words, with about 650 words vs 530 for Llama. But GPT-4o, at 8¢ for that particular transcript, cost 100 times more than Llama 3.1 8B did. But I also think that Llama 3.1 was good enough.
Is GPT is 100 times better? I don’t think so. 10 times better? No. Maybe 50% better, if I’m being generous. 10% if hard nosed. So it’s 1.5x better for 100x more expensive. That’s not worth it in my view.
What Else Can Follow This Pattern?
Last week I mentioned using LLMs to filter and sort incoming email. I think that’s a strong enough use case that we’ll see that pretty soon from the major email vendors and apps. I’ve seen hints that Apple is doing that in the next release of iOS.
That’s a classification problem as well as a summarization problem. The combination of classification and summarization lends itself to a lot of solutions. The low hanging business fruit (sales leads, service requests, etc.) I’m sure are being built out and refined already.
But for you and me, as individuals, we might:
Get customized summaries of the top news (especially if combined with my news reader app that learns what articles are important).
Summarize and ELI5 academic research.
I would say something about social media, but they’ve all become hostile to API access these days so never mind.
Sort through sale flyers to find things you might be interested in. Avocados for $0.50 apiece? Let me know about it! Broccoli on sale, hmmm, pass.
That’s just off the top of my head.
One key lesson from the YouTube summarizer demo is that getting the data in the first place is often just as important, and at least just as hard, as doing some sort of AI-wizardry on it. If you can get at data, you’re half-way there5.
Eventually, I’ll work Gilbert & Sullivan into this substack often enough you’ll all be experts in Savoy opera…
ChatGPT’s vision of baby Llama:

Awwwwwww. It’s Clip Bait, a portmanteau of clip art and click bait! I needed a good image for the article, you know?
I would not be able to, for example, just put an application on the web and turn you all loose on it if it used GPT-4o.
But not Livin’ on a prayer, to be clear.